
ReCon has become my favourite small conference about publishing and research. It’s held each June in Edinburgh. I attended it in 2015 and really enjoyed it. There were stimulating presentations on non-trivial topics, and plenty of interesting conversations over coffee and lunch. So I went again this year with high expectations that were not disappointed.
A few librarians attend, plus many researchers (mostly early career), some publishing people and information industry people. It is more research-focused than the UKSG or R2R conferences, and (to my mind) is more focused on cutting-edge topics. There is also a Hackday on the day after the conference but sadly I wasn’t able to attend that this year. Last year I learnt a lot from the Hackday.
Here is some of what I found most interesting about the conference. You can watch videos of the talks on the ReCon website.
Citation
Geoff Bilder (from CrossRef) is one of those people who is physiologically unable to give a boring talk. He promised us a rant but his talk, while vivid, seemed too carefully argued and well-worded to be designated a rant. He called it “The citation fetish”. He reminded the audience that citations can be inaccurate and distorted, leading to excessive concern with impact factors, h-indexes and the like. Then he complained that these metrics have gained too much influence on decisions about research careers. So far, so familiar.
Then Geoff surprised us by pointing out that we use the wrong words in connection with citations. When we talk about citations, we are talking about the inclusion of an article in a reference list. This is wrong we shouldn’t use ‘citation’ to denote the number of times an article is listed in a reference list. These are just references. Rather, when counting citations we should count each time an article is cited in the citing article. A cited article may be referred to several times in a citing article – but will only appear once in the reference list. This may seem a nit-picking point (I admit to thinking this) but Geoff suggested it is symptomatic of a problem with our citation habits – a concern with credit over reproducibility.
He also drew attention to ‘citation’ practice in the more informal world of blogposts. Typically a blogpost may include a link (just a hyperlink rather than a formal citation) to another web page (blogpost or something else). Sometimes a blog post may link to something which is in fact a DOI, i.e. a part of the world of formal literature. Sometimes blogposts may have more formal list of references at the end, with in-text citations. Some may include footnotes with links in. In blogs all of these different styles of citing and linking are intertwingled (I’d not heard this word before, but apparently it was coined by Ted Nelson). As bloggers we’re not thinking that hard about how we cite/link. We all do it, mixed up-wise.
Now Geoff got serious. He highlighted the Force11 data citation principles. The first three of these are: importance, credit/attribution, evidence. Geoff stated that the principles put too much emphasis on credit/attribution rather than on evidence (reproducibility), putting the cart before the horse.
I think this was the main point of his talk: citation practice should be at the service of reproducibility. Citing should be a way to help readers/researchers to follow through the arguments in a paper, and the execution of the research reported.
Focusing too much on credit/attribution harms this link. It occurs to me that there is a kind of diachronous Heisenberg uncertainty principle at work when we start to measure citations – the act of measuring affects future citation practice and thus deems all future measurements suspect.
Geoff enjoined us not to think magically about citations but to think critically and to doubt everything we think about citations.
After his talk I felt that we could quite profitably have sat around discussing what he said for the rest of the day. But sadly there were more talks to listen to. Luckily they were also thought-provoking.
Research data
Mike Jones (from Mendeley) had the difficult task of persuading us that we should be happy to trust his company (owned by Elsevier) with our research data.
I must confess I had missed the announcement that Mendeley now offered a data repository service.
It seems to have been around for about a year, though it was in beta for much of that time. Mendeley data is setting up as a competitor to broad repositories such as Figshare and Dryad, and will also work with Hivebench, recently acquired by Elsevier. Clearly Elsevier are putting together their own data ecosystem.
Mike rehearsed the well-known reasons underlying the current surge of interest in data sharing and data repositories. I liked his listing of the phases of data curation:
Storage (rescue) – Shared (needs incentives) – Discoverable (metadata) – Comprehensible (well-described/structured) – Valid (curation, review).
Finally, Mike mentioned that they are developing a search engine called Data Search which will search across multiple data repositories. Jim Procter on Twitter pointed out that its effectiveness will depend on the metadata.
I think it is useful to have another service in this general data repository space, but I think Elsevier will have an uphill battle to secure the trust of the research community. One of the questions from the audience highlighted this aspect.
Data viz
A major theme of the conference was data visualisation and there was a group of talks about this. Clearly it’s an on-trend topic as Nature also had a feature about it recently. http://www.nature.com/news/the-visualizations-transforming-biology-1.20201
Jo Young gave an introduction to the topic, taking us rapidly through the history of data visualisation from 1786. William Playfair invented several ways of visualising data. John Snow, with his famous map showing cholera hotspots grouped around a water-pump, was another pioneer, along with Florence Nightingale and Edward Tufte.
Jo gave us quite a broad definition of data visualisation, noting that IKEA self-assembly instructions can be categorised as such (personally I’d say they were fiction). Others include: Barplots, Boxplots, Network diagrams, Choropleths, Videos, Images / photos, Tables. I realised I am quite ignorant about this subject as I’d never heard of a ‘chloropleth’.
I’d never heard of Anscombe’s quartet either but Jo explained that it is a set of four small datasets having the same statistical features. However when visualised the datasets are revealed as being quite different. This provides a really persuasive example of the value of using dataviz.
Jo finished by giving some simple guidelines for designing data visualisations. She said that we are better at distinguishing different heights than different angles, so pie charts are not always the best choice for displaying data. Other advice included:
- consider your audience
- focus on the substance of the data
- pay attention to proportions and scales
- avoid 3D, avoid colour if it’s unnecessary
- don’t distort
- don’t add irrelevant data
- don’t prioritise design over data
Thus instructed in the basics, we then heard Pawel Jancz from NumberTelling extolling the advantages of the Tableau system. It allows you to interact with your data, link to sources, publish it online. Tableau public is worth a look.
Pawel then gave some more guidelines on constructing visualisations. If interested, I would advise watching the video of this talk as it was quite visual and I can’t do it justice in words.
Next up, Ian Calvert from Digital Science told us to ignore all the guidelines we’d just heard about. We should just get on with generating visualisations. He explained that dataviz can be a tool for researchers to understand and improve their data. I’d not considered this use case before but it makes a good deal of sense.
Ian explained that visualisation can be a path to clean data i.e. to data with fewer errors, that is easy to process automatically, and easy to link with other datasets
He showed us a real example, using data about published journal articles from 1500 to present and highlighting how dataviz can make errors and anomalies obvious.
Innovations in scholarly communication
Next followed the highpoint of the conference – a detailed presentation about research software tools from a pair of Dutch info-wizards:
Jeroen Bosman and Bianca Kramer
They have been looking at tools used by researchers at different stages in the research cycle. At first their project was called 101 innovations in scholarly communication – you may have seen the diagram they produced:
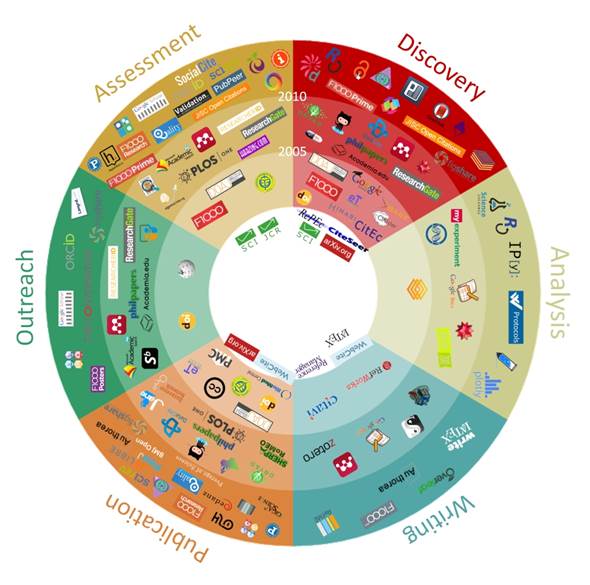
101 Innovations in Scholarly Communication: How researchers are getting to grip with the myriad of new tools. Image produced by Bianca Kramer and Jeroen Bosman.
Then the list of tools grew to 400, and now it is over 800. They have categorised each tool as either traditional, modern, innovative, or experimental and then examined whether you can characterise researchers by looking at the tools they use.
Another useful categorisation, aligned to the goals of scholarship, was their enumeration of tools as efficient, open or ‘good’ (or ‘ethical).
- Efficient – connected tools, publish neg results, speed of publishing, standards, IDs, semantic discovery (text mining), etc
- Open – peer review, lab notes, language (plain), open drafting, open access, CC-0/BY
- Good – declaring competing interests, replication, reproducibility, quality checks, credit where due, no fraud
Each tool is associated with one or more stages of the research cycle, divided into 6 or 7 main stages and further divided into 30 sub-stages.
I’d seen this diagram and thought it interesting but not especially useful. Silly me. Their next step was to launch a worldwide survey of researchers (translated into 6 languages apart from English). The survey gained over 20,000 respondents, showing which tools people use.
Their data is in Zenodo and their is a data note in F1000research. Their scripts for analysing the data are also shared.
A rather cool dashboard allows you to interact with the data (though it can be a little slow).
Now they can say how many tools a typical researcher uses: the median is 22, but the distribution follows a typical bell curve, slightly skewed to a higher number.
The number of survey responses to each sub-area also shows which are the busiest in terms of tool development and use – search and write win out, peer review is least busy.
They are now starting to work on a heatmap analysis to find out which tools co-occur.
This talk started all kinds of hares racing in my mind and I advise you to read some of their material, or look at the video of the talk. They will also be presenting at Internet Librarian International in October in London. I’m hoping to see them again at that time.
I recommend any librarian involved in publishing or research support to check out ReCon 2017 (no details yet but follow ReCon on twitter). See you there next year.
Many thanks for blogging about our event.
We will be back at the same venue around the same time next year.