I’m having a big clearout at home and have been discarding most of my collection of old concert programmes. These are a mix of concerts that I’ve sung in and concerts that I’ve attended, going back to about 1973. It’s a bit of a wrench to throw things away that represent old memories, particularly of my choral singing career, but I’ve decided that I am not defined by old bits of paper. I am keeping just a handful of them.
One I am keeping is one of the oldest – an old concert programme from 1974. It was a folded A4 sheet, printed in that blue ink that used to be commonplace in the 1970s. It was for a concert of Handel’s Messiah and I’m pretty sure that I sang in it. It was memorable as both the first concert I had sung in that was not a school thing, and also the first time I had heard a countertenor singing live. The programme is dated ‘Saturday 2nd March’, but with no year specified. That day was a Saturday in 1968, 1974 and 1985 and 1974 is the only year that makes sense to me.
The previous year my school choir (Salesian School, Chertsey) had performed the Messiah, under our new head of music Father Thomas Carroll. This school performance was the first time I’d sung such a large piece of music, with soloists and orchestra. The soloists were competent but not fantastic. I remember the soprano was one of the nuns who taught at the linked girls school and she had a rather shrill tone. The tenor was a teacher from another school – he was called Trevor I recall – and I experienced a sense of jeopardy whenever he went for the top notes. Anyway, me and my mates in the choir had learnt the music pretty well and it was very rewarding to sing – the first of many times I’ve sung the piece.
Then in March 1974 Father Carroll arranged for a few of us tenors and basses to join in another performance, in south London. This was being put on by a young man, Peter, who was a past student of Fr Carroll at the Salesian School at Battersea, where Fr Carroll had taught music before he came to us at Chertsey. Peter needed some extra male singers to boost the choir – there’s never enough tenors and basses – and he turned to his old teacher to provide some young voices. It was a bit of an adventure for us. Fr Carroll drove us in the school minibus all the way to Streatham.
In my memory the concert took place in the Catholic cathedral at Southwark, but I think I must have imagined that. The fact I possess this programme suggests it must be from the performance that we sang in. I don’t think I would have attended a concert in Streatham, south London to listen to Messiah in 1974. I didn’t make that kind of excursion far from home back in 1974. I’ve looked at my old 1974 diary for corroboration but there was nothing marked in for that date.
I don’t remember much about the performance. I had a general sense that it was a big deal (well, it was for me but probably not really on the scale of things). The church we sang in was far more atmospheric and acoustically satisfying than the school hall that we had previously performed in. The orchestral players were good – probably semi-professional players – and the soloists were far better than at our school performances. The sound of the countertenor soloist in particular entranced me – so pure and bewitching. His aria ‘But who shall abide the day of his coming’ stands out in my memory.
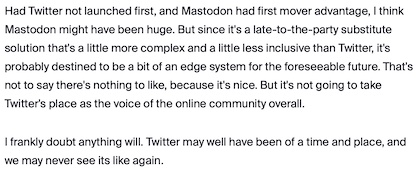
I was pleased to re-find the actual programme for this concert and to remember that occasion. When I looked at it I was somewhat astonished to read the names of two of the soloists: Rod Williams and Ms Rozario. Both are superstars of the UK and international classical music scene today. I couldn’t believe that as a schoolboy I had sung Messiah with these two in a church in Streatham.
I looked more carefully, and was surprised to see that Ms Rozario was listed as a contralto. She is known as a soprano, able to sing very high top notes, and famed for her work with John Tavener’s music. Rod Williams is known not just for his fine baritone voice but he also conducts and composes.
I then looked at these two singers’ Wikipedia pages. Patricia Rozario was born in 1960, so she would have been 14 years old at the time of this concert. It seemed unusual and unlikely that she would take on a solo role at that age. Roderick Williams was born in 1965 so he would have been just 9 years old. That seemed impossible.

Programme for performance of Handel’s Messiah, 1974
I felt perplexed, as though I was experiencing some time warp phenomenon. Then I looked at the programme more closely. The contralto soloist was named as Rita Rozario – not the now-famous Patricia Rozario. The bass soloist was named as Rodney Williams – not Roderick Williams. I don’t know where Rita and Rodney are now, nor whether they were ever mistaken for Patricia and Roderick in the past 50 years.
If I had been more switched on I might also have noticed that the concert was conducted by Peter Hook, co-founder of the popular beat combo Joy Division. I’m not familiar with their music. He was born in 1956, so he could almost have been conducting Messiah in 1974, but I note that he was born in Salford and attended Salford Grammar School, not the Battersea Salesian School. So it was probably a different Peter Hook.
Just imagine that fantasy concert though – Patricia Rozario, Roderick Williams, Peter Hook and Frank Norman all on one stage singing Handel’s Messiah!







![Tweet: 'hang on honey i just need to check my account on Twitter, Mastodon, [etc etc]'.](https://occamstypewriter.org/trading-knowledge/files/2024/09/Hang-on-honey-I-just-need-to-check-my-account-on-Twitter-Bluesky.jpg)