
Last week some of us published a paper trying to improve the way p-values are interpreted by suggesting this be done on a more continuous scale (here’s another link to the paper: hopefully one will go to a readable version). This caused a lot of activity on twitter, and a response from Daniel Lakens, who is a 20% statistician (and is therefore not significant). His post is a strange beast: the main message is diluted by the way he contradicts himself.
Our paper was an attempt to make an improvement in one (small) part of scientific inference: how p-values are communicated. Our argument was that when we write our results sections, we shouldn’t use the dichotomy of “significant” or “not significant”, but instead communicate a continuum of interpretation of p-values as evidence, e.g. rather than writing “The effect of x on y was significant (P = 0.03)”, we suggest “There was (only) moderate evidence that x has a (positive/negative) effect on y [(give effect estimate), P = 0.03].” We though this would be a useful, if small, step to improve the interpretation an reporting of significance tests in practice.

There was a lot of reaction on twitter, most supportive, but not all. In particular, Daniel Lakens did not like this at all:
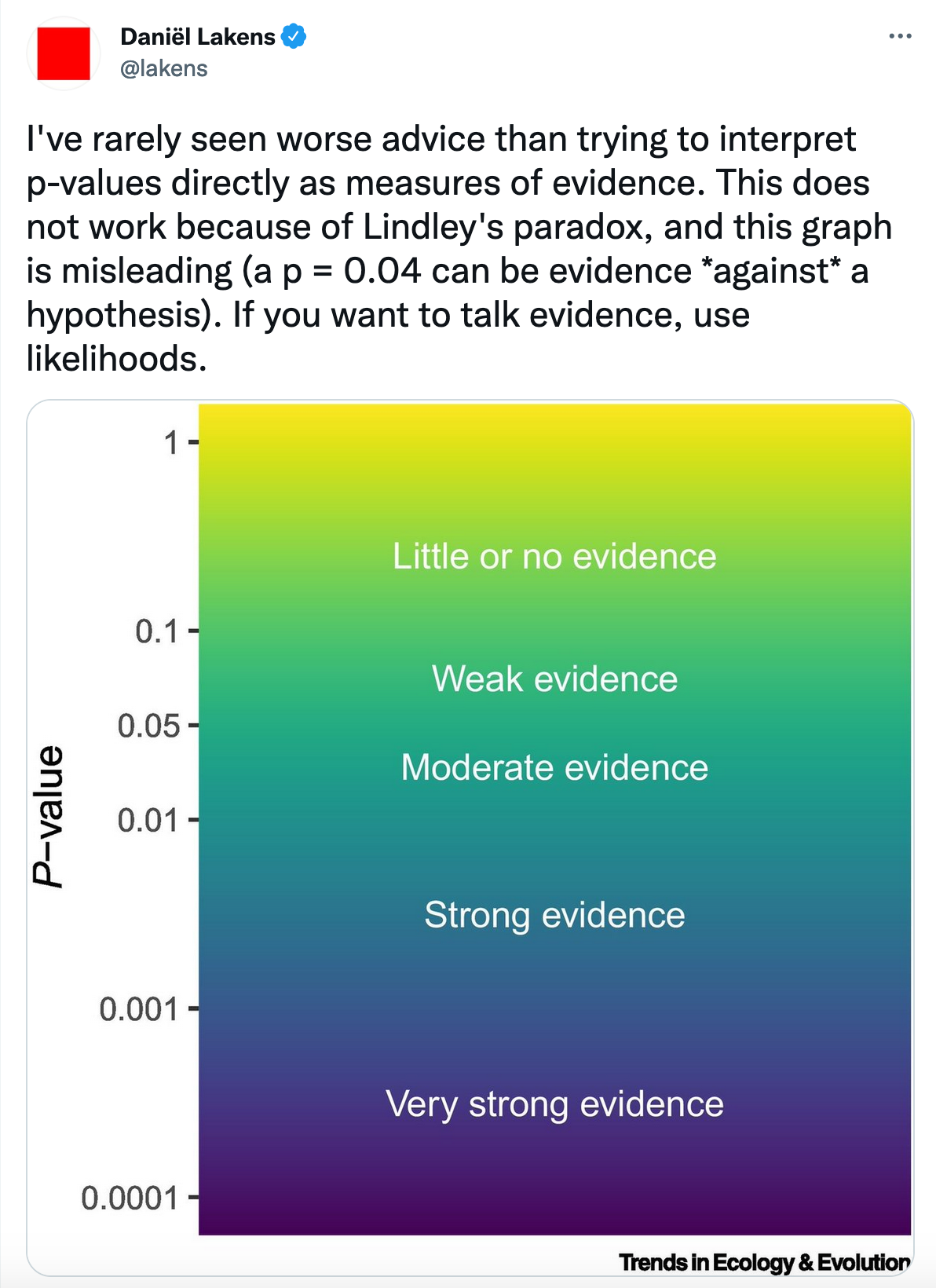
After some discussion (which went around a bit, as twitter discussions are wont to do), he wrote a blog post to clarify his views. I think we actually agree on the main point of disagreement, but if we get there by different routes.
Lakens’ argument goes roughly like this:
1. p-values only make sense when the null hypothesis is compared to the alternative hypothesis
2. p-values should be treated as p-values. But as p-values in the Neyman-Pearson null hypothesis statistical testing framework.
3. There are a variety of coherent statistical frameworks that are used, and people should be able to use them.
The incoherence between point 2 and 3 should be clear (not all coherent statistical frameworks use the Neyman-Pearson appraoch), especially as I have over-simplified it. But aside form the bit about Neyman-Pearson null hypothesis statistical, we more or less agree. Lakens sees disagreement because, I think, he is taking a narrow view of the inferential process, and so sees our way of looking as p-values as incoherent. Unfortunately for him, he can only make his argument by destroying the “p-values should be treated as p-values” slogan.
Let’s walk through this. First, what is a p-value mathematically? As we say (and I assume Lakens agrees), it is the probability of observing a specific data summary (e.g., an average) that is at least as extreme as the one observed, given that the null hypothesis (H0) is correct. I don’t think I’ve seen anyone argue that that is incorrect. The way it is used is (informally) is to say that if the p-value is low then we decide that the null hypothesis is wrong, and instead we accept the alternative hypothesis. This developed into the formal Neyman-Pearson approach:
1. specify the null hypothesis, H0
2. specify the alternative hypothesis, H1
3. Calculate your statistic, and thus p-value
4. If p<0.05, declare it significant, reject H0 and accept H1
Our argument maps nicely onto this, but rather than accept/reject, we are suggesting we move towards a more graded way of describing p-values, as summaries of evidence, e.g. “There was no evidence that x has an effect on y [(give effect estimate), P = 0.53].”, or “There was very strong evidence for a (positive/negative) effect of x on y [(give effect estimate), P < 0.001].” (both of these are from our Table 1). Note that the examples, indeed all our examples, are couched in terms of the evidence for/against the alternative hypothesis.
Lakens didn’t notice this, probably because we didn’t spell it out. In our Box 1 we presented p-values as being about rejecting H0 (a Fisherian approach). Which, strictly, is all they are. The alternative hypothesis does not (usually) appear in the calculation1, so if you want to interpret p-values as p-values, then you shouldn’t refer to H1 at all. At best they become goodness of fit tests: with a single test a low p-value suggests that the model for the null hypothesis is unlikely to have produced as extreme a value.
Even though he wants us to interpret p-values as p-values, Lakens doesn’t actually discuss what a p-value is. Instead he explains the Neyman-Pearson approach, which is a framework for hypothesis testing built around p-values. In other words, he is arguing not that one should interpret p-values p-values (i.e. a statement about the improbability of more extreme data given the null hypothedsis), but only as Neyman-Pearson p-values, i.e. as a formal comparison between two specified hypotheses. If one is using a Fisherian p-value, you can’t interpret your p-values, because… what? They are not p-values? And if you are actually carrying out a goodness of fit test, where the null hypothesis is what is of interest… what? In this case, the alternative hypothesis is that the null hypothesis is wrong.
So one has to be Pure of Heart and accept the Teachings of Egon and Jerzy (revised edition). Except:
I will go out on a limb and state some things I assume most statisticians agree on. First, there are multiple statistical tools one can use, and each tool has their own strengths and weaknesses. Second, there are different statistical philosophies, each with their own coherent logic, and researchers are free to analyze data from the perspective of one or multiple of these philosophies. Third, one should not misuse statistical tools, or apply them to attempt to answer questions the tool was not designed to answer.
All of which I would agree with: there are different approaches, and specifically I am not arguing that the Neyman-Pearson appraoch is wrong. But Lakens seems to be arguing that all ways are right, as long as we follow the Nayman-Pearson approach. Given that p-values don’t explicitly answer questions about H1 2, one could even be naughty and argue that one shouldn’t use them to answer questions about H1.
In reality, I actually think we are not so far apart from Lakens, and he missed the importance of what was in our tables (and we overlooked the importance of them in making a complete argument). We all agree on the mathematical definition of a p-value. We also agree that a small p-value should be interpreted in the context of support for the alternative hypothesis. The difference is that we didn’t explicitly state it. I think the excuse we’ll use in public is that we were only focusing on one part of the use of p-values, so didn’t go into details about the others. But our examples did, at least fairly explicitly, put them in the context of the alternative to H0. So we make the leap from rejection of H0 to evidence about H1 in the informal interpretation of p-values, rather than put it in a formal framework. That reflects the way we see p-values being used in practice: not with null and alternative hypothesis being explicitly stated, but with them often being implicit, but clear.
In summary, what we were doing was a reflection of how we saw p-values being used, for example, in Schools of Psychology, whereas Lakens is more interested in the sort of formal framework that emanates from Mathematics departments. In general neither is really wrong, I think, but when talking to one audience one has to sacrifice aspects that the other might think important.
1 OK, OK. First, some tests are set up so that H0 and H1 are directly compared: essentially, likelihood ratio tests do this. Also, the test statistic usually reflects H1, e.g. if H1 is that the means of two treatments are different, then the difference in the means makes a good test statistic.
2 See footnote 1.
I don’t think your foornotes go far enough.
The Neyman-Pearson approach as described is intellectually incoherent, because there is no assessment of whether the data is MORE likely under H1. As stated, I could hypothesise as follows:
1. Specify H0: This is a fair coin, and the probability of throwing heads is 0.5
2. Specify H1: This coin is a fake with two heads, so the probability of throwing heads is 1
3. Calculate statistic: I threw ten tails in a row, which only has a probability of 1/1024 if H0 is correct
4. Since p < 0.05, reject H0 and accept H1
This is palpably absurd. If you want to use your p value to make any kind of claim about H1 as wel as H0, then your test statistic has to somehow incorporate both hypotheses.