
A few weeks ago Science published a paper which claimed that biodiversity was important for the functioning of dry grasslands. This claim was strange because the analysis suggested that biodiversity wasn’t very important – it only explained about 4% of the variation in the data, whilst the abiotic components in the model explained about 50%. This caused me to look a bit deeper at the paper, and also to think a bit more about one particular aspect of the authors’ argument: how we can infer processes from observational data (i.e. where we don’t manipulate the conditions).
In their paper, Maestre et al. argue that the effects they see will be even stronger than estimated:
“[b]ecause we did not experimentally control for other abiotic and biotic factors that are known to affect ecosystem functioning, significant relationships would indicate potentially strong effects of richness on multifunctionality”
Which is utter rubbish. As with any good scientific discussion, the response can be summarised with an xkcd cartoon:

(check the roll-over text too)
Because the authors didn’t “experimentally control for other abiotic and biotic factors that are known to affect ecosystem functioning”, any significant relationships could be spurious. Denying this would mean having to accept the stork theory of reproduction.
But there is a kernel of truth in the assertion; the authors were unfortunate in choosing a horribly wrong justification for a more reasonable statement. Because if there is an effect of species richness, then the authors are correct to suggest they are under-estimating the effect. And I suspect underestimation like this is rife in ecology.
The Problem: errors in variables
I can illustrate the problem simply enough. Imagine we have a regression problem where this is our data:
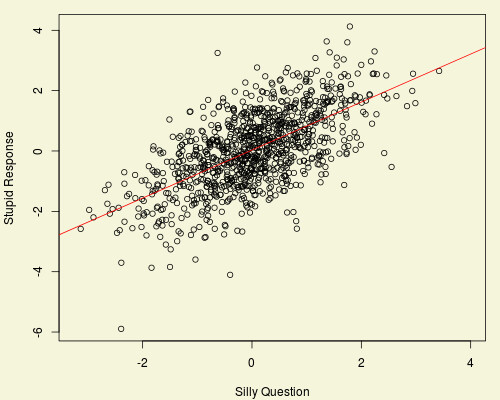
Now imagine that rather than having the actual covariate, we only have a corrupted version. Here I have added some random noise (the response is the same):

The corrupted data is more spread out, and the regression line for the corrupted data (the blue line) has a shallower slope than the regression for the original data. This is despite the correlation between the original and corrupted covariate being 0.9 – the pure and corrupted variables are pretty similar.
Of course that’s only one regression. But the pattern is general: when you have an error in your variable (i.e. what you measure is only correlated with what’s truly causal), the regression coefficient is biased towards zero. We can get an idea about how much by doing lots of simulations:

The blue line is the true regression coefficient. Even with a strong correlation there is a significant bias: the estimated slope is half if the correlation is about 0.7 (which is still pretty strong). With a correlation of 0.9, the regression coefficient is about 80% of the correct value.
Does this screw up field ecology?
Back to the paper. The authors only estimated species richness, so if species richness were genuinely driving ecosystem function, there almost certainly will be some effect of the error in the variable. But even if it is estimated perfectly, I think the same problem is still present because I doubt that species richness per se is what would affect productivity: the frequencies of the different species will also matter (imagine an ecosystem dominated by one species, with 19 other species which are all very rare – I think this would behave more like a single species ecosystem than one with 20 species). Even if biodiversity does affect ecosystem function, species richness is not the driver: that is will be more complex function of richness and relative abundance. But species richness is probably correlated with this function, so the “true” effect of biodiversity is underestimated.
My hunch is that this problem is pervasive in ecology. We measure all sorts of things and see if they have an effect on nature, for example if water bird populations are affected by mean winter temperature. But mean winter temperature itself is probably not the driver – it could, for example, be the effect temperature has on freezing ponds and lakes. But the precise mechanism would be difficult to get at – is it the date each pond freezes over? Or freezes over enough that not more than 3 ducks can sit in the water? Or is it the length of time it’s frozen over or…
You see my point – the mechanisms are complicated, and we only measure surrogates. Indeed, in most cases we can only measure surrogates. The depressing conclusion, then, is that we are underestimating the effects we are looking at, because even if we have found the correct ones we usually can’t estimate the accurately. So our models are wrong (although they may still be useful).
We might not have to worry too much if the relationship between what we measure and the true driver remains constant. Then the bias is stable, and although our inferences are biased at least the bias doesn’t change. Our predictions will still be valid, albeit not as good as they could be. If the relationship does change then we could be screwed, though.
All of this just makes interpretations more messy. If we estimate an effect of species richness (say), it could be that the true effect of biodiversity is larger and we are only measuring an indicator, or it could be that there is no effect, but both ecosystem function and species richness are affected by the same abiotic drivers.
I wonder what you, my reader, thinks? Is this something to be seriously concerned about? I think the problem needs to be assessed from a wider perspective than I can give.
Help?
Brilliant. One of your best, perhaps, especially given the seriousness of the subject matter. There ought to be mandatory biostatistics training for all scientists and principal investigators, so that these basic points about interpretation – that you have indicated – can be imprinted onto their minds, for this doesn’t happen just in Field Ecology and Biodiversity; this is a common problem in biology, most acutely in clinical medicine.
Even if – because of the reasons you have mentioned – the true effect of a phenomenon can’t be adequately estimated with the tools one has, this is the kind of information that should go into the discussion of every paper. Scientists need to learn to live with these small and unavoidable (and perhaps even temporary, in the absence of better metrics) inaccuracies, especially ones which do not significantly impact the outcome or analysis.
But… but… Science? I don’t understand how these high profile journals don’t insist on more rigorous statistical analyses, or indeed, why the reviewers for these journals can’t pick up on exactly what you have commented on. It is a disservice to the scientific community.
About a couple of years ago, I had an occasion to engage the authors of a Nature article about their use of faulty statistics. I even reanalyzed their raw data and pointed out some places where there were problems. Eventually, the editor decided that since the article was published, the discrepancies in statistics were not major enough(!) to warrant post-publication revisions. They published a corrigendum (an inaccurate, incomplete and rather insincere corrigendum I thought) and I let it go at that. But it certainly diminished the respect that Nature had in my eyes.
Thanks. I think Science are going to publish a comment along similar lines. I still have a post to finish about AIC, inspired by the same paper.
At least you got your name in Nature. 🙂
Bob – very sensible stuff, nicely put. And I know it’s tangential to this post, but your comment: “imagine an ecosystem dominated by one species, with 19 other species which are all very rare – I think this would behave more like a single species ecosystem than one with 20 species” sort of sums up the idea of ‘effective number of species’ which is what people are trying to get at using Hill numbers. Interesting paper on this by Leinster & Cobbold on early view (possibly now published) at Ecology.
Kausik – and yet you try explaining to your boss why you choose not to publish in statistically dubious journals like Nature & Science and they just don’t understand!
Hi Bob – Nice post. It would be good to note how to address this problem. Measurement error in the explanatory variable could be modelled quite easily, especially with hierarchical models by including the estimated error in the model:
Y = a + b*(X + xerror) + yerror,
rather than the typical regression:
Y = a + b*X + xerror).
But that means that xerror needs to be estimated independently of yerror (I’m assuming that xerror and yerror cannot be estimated from just data on X and Y).
But if the measurement error is known (and it should be), then Model II regression should account for this. With hierarchical modelling, it would seem quite easy to do.
Having said that, I can think of only a handful of my papers in which I used the above, and it has never been in response to the comments of editors or reviewers. It just doesn’t seem to be on the radar of ecologists.
How to deal with things when X only has an indirect influence on Y seems more difficult, but then an imperfect relationship seems a genuine result. It is just a matter of careful interpretation – X might be only a surrogate measure for the variable that really drives the relationship.
Mick (mickresearch.wordpress.com)
Most of Ecology is built on statistical dubiety. I’d say most of science was, but that’d be beyond my confidence/credible intervals.
But, but, but… going back to Tom’s tangential point, the number of species is (I agree) a poor metric for biodiversity. So is any metric based only on the number of species and their density sampled at a single point in time (Steinhaus, Simpson’s etc indices). I almost hate myself for saying it, but different species take different roles (and/or provide different ‘services’) within the ecosystem. Diversity–Stability regressions don’t actually do much to improve our knowledge of what mechanisms underlie different measures of ecosystem stability.
What we shouldn’t be doing is more basic ‘diversity–stability’ data-dredging. What we should probably be doing more is asking how big that ice hole is compared to the ducks’ arses.
Hi Bob – This is a nice post, and definitely relevant topics. It is not the first time, and surely not the last one, that a large sample size allows someone to say: ‘X clearly influences Y (PR2 is less than 4%. Statistically significant but biologically irrelevant? You know, p-values and all that…
And it’s amazing, because the bias towards 0 of a regression coefficient in the presence of sampling error in the covariate (formally, the “attenuation” of the coefficient), is very well-known in statistics: Charles Spearman indeed introduced the term in 1904, but ecologists have virtually ignored this effect (should I say ever since?)! Ok, it is now universally acknowledged that ignoring sampling error in abundance censuses artificially increase the estimated magnitude of density dependence, but the effect of sampling error in environmental covariates seem out of scope from ecological research. In other words, all ecologists deal with sampling error, in the majority of the cases simply by ignoring it. After all, this is a way to deal with it.
Following Michael McCarthy’s post above, when estimating parameters in a time series ecological problem (e.g., environmental impacts on wintering water bird populations), a straightforward solution is simply to specify a state-space formulation for the environmental component, besides the now “general” approach of doing so with the abundance data. Of course, this would entail having independent information on the amount of observation error in the environmental drivers.
And I’m not ashamed to point out that we have just done precisely that, in a recently published paper. And as a cosmic coincidence, it is precisely on the analysis of the effects of multiple environmental drivers on the dynamics of a wintering water bird community… We had information on the sampling error of an environmental driver, and we found that the strategy of simply ignoring it is not a choice: inference on environmental forcing can be severely distorted, and effects even reversed; and it seems the effects of sampling error in the environmental drivers propagates to the estimation of density-dependence, which seems even worse.
The strategy of averaging a set of candidate environmental predictors, for example, or to conduct a PCA to deal with a just few components, or even to use the somewhat reified large-scale climate indices, seems like an awful strategy: sampling error propagates across. In other words, a sum of several random walks simply yields a random walk. The bottom line is, I guess, to always estimate the magnitude of sampling variability in ANY variable we measure, and incorporate this estimate in our models. There’s not short-cut path to the truth.
Thanks for your comments. The state space approach Mick & Pablo have mentioned is the obvious Bayesian one, and I’ve used it at least once. I’ve also suggested it as a reviewer, which didn’t go down well.
Pablo – summing across candidates will help if they all have the same effect (because it reduces the sampling variation). That’s what PCA does, but of course it also estimates the loadings, which adds in additional error. And if you only use the largest components, you can miss the important ones (because there’s no reason to believe that the explanatory power of the variables should lay along their PC’s).
I’ve been wondering whether a paper about these issues is in order, but haven’t yet worked out the hook to get me started.
Bob – Ok, sampling variability is reduced in PCA, but only when the sampling error for each candidate is completely random, and all have the same effect (?); I mean, at least short bursts of systematic sampling error (over- or underestimation) are to be expected, in particular in short ecological time series, and it’s hard to see how these (random) burst can exactly cancel each other across variables, and how a set of candidates can have precisely the same effect; the point, I guess, is that systematic sampling error does not have a large effect on parameter estimation relative to random error (it is like adding a constant) and, given that longer time series contain shorter “random portions” of systematic error, the problem with sampling error is perhaps worst in long vs. short series… which seems rather counterintuitive, and highlights the insidious nature of sampling variability. Again, I think the best approach is to empirically estimate sampling error, and live dangerously with it. Or perhaps I’m missing something here…
Great to know you are planning to write something about all this! So was I, so is great that someone with a googolplex of experience will eventually do the job…
Sorry it took so long to write this: the errors in variables problem leading to attenutation is, I agree an over-looked one. The paper by Pablo is a very nice example of when things can go wrong.
Here’s another major problem with errors in predictors. Imagine that I am studying plant growth and looking to see whether plant growth is affected by rainfall or temperature. For arguments sake, lets say that plants growth is driven by rainfall, so that when it rains more they grow better. The problem is that temperature and rainfall are correlated, so when it is rainy the weather is cool, and when it is hot there is no rain. So there is collinearity between the predictors.
Ordinary multiple regression (despite what many people think) is actually very, very good at unpicking such effects. Certainly much better than many dodgy alternatives based on dubious residual regressions etc.
However there is a problem when there are errors in the variables: imagine that temperature is measured very accurately, but that rainfall is measured with a lot of error. In that case, it may be that measured temperature correlates better with actual rainfall than measured rainfall does! If this happens then a regression will tell us that temperature is the better predictor and we will get things wrong. Ouch!
Having said all of which – any regression has to be understood as an estimate of the relationship between the measured variables. i.e. in the above example, concluding that measured temperature is better correlated with plant growth than measured rainfall is not actually ‘wrong’: it does because this variable is better correlated with the true driver (true rainfall). If we predicted future observations then we would do so better using measured temperature than using measured rainfall!
Pablo – You’re right, estimating sampling is the right way to go. But I think you’re missing a point about sampling error – larger samples will dilute any random bursts of error, and this effect is bigger than the increased chance of having a random bursts of error.
BTW, I’m only thinking about writing something, so if you’ve got some ideas, email me and let’s do something together.
Elton – The problems with multiple covariates can be even worse – it’s possible to over-estimate the effect of one covariate if they both have error (and there are lots of correlations). If I get time I’ll have a deeper look at that, but it’s another reason to wonder how we get anything useful out of observational data. There are just so many things that could go wrong.
A colleague directed me to this comment on the paper by Maestre et al, which comes across to me as a rather superficial and dismissive evaluation of what is actually a remarkably interesting and potentially very important paper. It is already well known that observational and experimental treatments both have their relative strengths and weaknesses, and while Bob’s opinions about observational studies are immediately apparent through his comments, many experimental studies on the same topic that do “experimentally control for other abiotic and biotic factors that are known to affect ecosystem functioning” can also (and have been) heavily criticized on statistical and other grounds (see Michael Huston’s famous ‘hidden treatments’ paper for starters). So to use labels for Maestre’s excellent paper such as ‘utter rubbish’ and with accompanying cartoon seems inappropriate at best.
If Science is indeed publishing a response to this paper as Bob suspects then this is interesting and I look forward to reading it. The main authors of the paper, such as Fernando Maestre and Nick Gotelli (statistically very literate ecologists hardly prone to writing ‘utter rubbish’), would be given the opportunity to reply — I am sure they would have ready answers and I look forward to reading their response too. These sorts of exchanges are usually peer reviewed; the reader can then read the exchange and then make up their own mind about the work based on peer-reviewed scientific argument rather than non-reviewed opinions.
Why isn’t the sentence I described “utter rubbish” utter rubbish? I’ve laid out my reasons, so what’s wrong with them?
I’m sure readers can make up their own minds on this exchange without it being peer reviewed.
Hi Bob, I got here via twitter. I think like the Maestre et al paper, you may have extrapolated your inferences beyond what is prudent or reasonable.
For one, while I agree, their statement that:
“[b]ecause we did not experimentally control for other abiotic and biotic factors that are known to affect ecosystem functioning, significant relationships would indicate potentially strong effects of richness on multi functionality”
doesn’t make a lot of sense, your description of what they stated:
“In their paper, Maestre et al. argue that the effects they see will be even stronger than estimated”
is equally mis-representitive: they didn’t say “effects would be even stronger than estimated”
As Dave Wardle gently alludes, Nick Gotelli LITERALLY wrote the book (several in fact) in ecological statistics and is widely known to be a very careful and sober scientists. While I do think there is a lot of utter rubbish in science and in Science, this doesn’t seem to me to be the best example of it. At Nick at least doesn’t need to take a stats course.
Your rant about error in estimating independent variables in science, is true, but I think largely irrelevant to the paper and issue at hand.
For one, they were indeed interested in richness per se, and not in evenness. Richness (the number of species present, regardless of their relative abundances), can in fact effect ecosystem properties and is usually what ecologists are focused on in this sort of study.
Iv’e published a fair amount in this field and I do agree there is a lot of rubbish in the literature and that the relative effect of richness on function is often greatly exaggerated. I once submitted an experimental paper to Ecology in which we found zero effect of richness and very strong effects of species composition and the editor rejected the paper as a “failed-experiment”. In fact, in most of our experiments, richness indeed explained a tiny amount of the variable of interest. I suspect there is a strong publication bias that keeps the positive findings coming out and in top journals like Science, Nature, Ecology Letters, etc. There is also IMMENSE pressure from editors and reviewers on authors to oversell the positive effects of richness.
But I agree with Dave: there are some unique aspects to this paper, especially the global synthesis of data. It may be imperfect science – what isn’t – but the stats as far as I can tell are not somehow bogus as you allude.
That is true, they don’t state this. But how else are we to interpret it? Their effects are weak – they only explain a few percent of the variation in the data. So their statement that they are showing strong effects can only mean that they are underestimating the effects.
First, it’s clear from reading the paper that they are interested in biodiversity – read their introductory sections and they discuss “biodiversity” not species richness. It’s clear that they are using species richness of perennial vascular plants as a surrogate for biodiversity. I don’t have a problem with people doing that, but I still don’t think it’s what is causal, for reasons I explain in my post. Just because the authors were interested in species richness doesn’t mean that that’s what was causal, and I think we should be trying to get at the latter. This is why the my post is relevant: unless species richness is itself directly causal then all of the problems I discuss are relevant.
Finally, I certainly wouldn’t say that the stats are “bogus”: they can be improved, but I’ve seen far worse. The big problem I have with the study is that it mis-interprets the results of the analysis. The authors acknowledge that species richness doesn’t explain much of the variation, but they still claim that their results means that biodiversity is crucial to buffer effects of climate change. But if the results says anything (and of course my post gives plenty of reasons to be cautious about any conclusions) it’s that species richness isn’t that important for ecosystem function: abiotic factors are much more important, both individually and as a group (compare the standardised coefficients in Table S14).
Yes, they use species as a surrogate for biodiversity write large. But, that’s the essence of the field of Biodiversity and Ecosystem Function (see Hooper et al 2005 for an excellent review of the whole endeavor). So why just concentrate on richness? Is our whole field mad? No. Rather, the use of richness as a predictor for function rests on solid theoretical and applied ground – namely coexistence theory (the former) and the ability to manage an ecosystem under limited information (the latter). This goes double for the idea of Multifunctionality that Maestre et al. were trying to address.
Yes, composition, evenness, and more clearly matter if we are to look at biodiversity writ large (I’ve even got some stuff in review on this), but, this piece was firmly grounded in past theoretical and empirical work. I agree that a more robust framework that had a more solid foundation in causal modeling and the incorporation of error (yes, yes, I’m talking SEM, you know me to well) could have clarified the analysis. But I suspect that the qualitative result would not change – that there is a signal of species richness in the data. Could there be a clearer comparison of effect sizes? Yes. Would the qualitative result change? I really don’t think so. Does the qualitative result based on the data set at hand and its concordance with what we have found in the BEF literature coupled and the growing recognition that experiments are only going to get us so far in this field of inquiry merit this paper to make it into Science? That’s a more subjective one. I, for one, was greatly intrigued.
The data is available, though. Might be interesting to compare the standardized regression coefficients between terms in the models selected by the AIC analysis.
@Dave Wardle,
Dave, it’s disappointing to see you respond to this post on such spurious grounds. As I’m sure you must know, the identity, fame, or expertise of the authors of this Science paper is irrelevant to the correctness or otherwise of their statistical interpretations. I’m sure you wouldn’t claim that anyone is infallible. But if not, why note the authors’ identities at all? Invoking their identities can only be read as an attempt at proof by authority. That’s the sort of thing the Catholic Church does.
Further, I don’t understand why you would imply that posting criticisms of a Science paper on a blog somehow doesn’t give the authors a chance to respond. I hope you didn’t mean to imply this and will clarify. After all, a blog posting, on which anyone is free to comment, gives the authors more chance to respond than, say, a private face-to-face conversation (and I’m sure you don’t object to those!) Indeed, you or anyone is free to share this post with the authors of the Science paper so as to ensure that they’re aware of it and can comment if they wish. Did you do that?
I’m also disappointed by your implication that criticisms that aren’t peer reviewed somehow aren’t worthy of reply. As Bob notes, I’m sure you are capable of judging the merits of any commentary you read, independent of the venue in which it was published. Again, I hope you didn’t intend this implication and will clarify.
Finally, I’m disappointed to see you respond to Bob’s criticisms by noting that completely different ways of studying this topic are subject to their own criticisms. Bob never denied that. Indeed, it would be silly to deny, since every approach has its own strengths and limitations. But if noting that was an adequate answer to criticism, no criticism of any approach would be possible.
Perhaps you thought that in commenting in the way that you did you were being polite. But to be frank, I think your comment could easily be read as patronizing. I’m sure that wasn’t your intention at all, but I can definitely see how it could be read that way.
@John Bruno,
I’m disappointed that you would defend David’s irrelevant invocation of the authors’ identities. Are you seriously claiming that it’s impossible for a paper with Nick Gotelli’s name on it to misinterpret the results of a statistical analysis? Because if so, you have a higher estimate of Nick Gotelli’s own abilities than Nick himself. I’ve criticized Nick’s null modeling work quite stringently over on the Oikos blog, and Nick has been perfectly happy to engage with my criticisms rather than simply invoke his own name in his defense. And again, if you’re not claiming that Nick is infallible, why invoke Nick’s name, (and the fact that he LITERALLY wrote a book!) at all? Even as a purely rhetorical strategy, meant to support a substantive point, such rhetoric is a bad idea. It just raises the suspicion that any substantive points you have to make won’t stand up to scrutiny, thereby forcing you to fall back on proof by authority.
Bob has raised a legitimate and important issue and made a perfectly fair point. Further, he has done so in what I think is an admirably clear and precise way. For instance, it’s perfectly clear that he is criticizing a particular quoted statement in the paper, not everything about the entire paper, or every paper on this topic. It’s also perfectly clear that he’s not criticizing the authors personally, or questioning their competence, as indicated by the facts that (i) he never says anything like “I question the authors’ competence”,(ii) he talks at length about how the issue he raises is a widespread and challenging one in ecology, and (iii) at the end he confesses that he himself is unsure how best to address the issue and asks for reader feedback. This excellent post deserves (and I’m glad to see many other commenters providing) substantive responses on the merits.
OK, for the heck of it, I downloaded the data and ran the analysis that corresponds to Table 1. I think something is a but off, as my AICc values are slightly different from theirs, but, just for some additional information, here are the standardized regression coefficients arising from the following model (I’m using these rather than the AIC weights of Fig 2 as the meaning is quite different):
So, ~0.17. Not huge, but, and soil content, elevation, and one of the PCAs appear to have a stronger relationship, but, it’s within the ballpark of the other predictors. N.B. averaging over all of those models, things look more or less the same.
jarrett – the standardised estimates are given in Table S14. Species richness is the 5th most important variable, and less than half as strong as sand content (I wouldn’t describe this as “very similar”, which is what the authors do). For me this is a qualitative difference in interpretation: it would seem bizarre to focus on such a minor variable if they were all to be judged the same.
I take your point that it’s reasonable to look at species richness, my argument is more that it shouldn’t be seen as being causal per se, rather it’s linked (hopefully strongly) to whatever is. I guess it’s best viewed as a useful statistic to summarise the complex processes that are occurring.
Jeremy – thanks for the support. If Dave and John don’t respond it’s probably because they haven’t seen your reply: there’s been a bit of a gap between their comments and yours. The issue of appeals to authority is curious: we all do it, and I think we often have to. But it doesn’t trump a reasoned argument.
Incidentally, I think I can win the authority game too, I have Proper Statisticians I can wield (whether they want it or not). 🙂
Bob: does citing yourself count as an appeal to authority? Or will you just start citing DI ‘textbooks’ to demonstrate some other pertinent point?
There was quite a bit going on here so I wrote my own blog post as a reply. But fundamentally I think that Fernando was saying that biodiversity explains at the very least some of the multifunctionality. The location of the error (in x or y) behave the same if you’re interested in R^2 values. I wrote a whole post in reply http://currentecology.blogspot.ca/2012/04/much-ado-about-something-b-nothing.html
As a side note I think that Bob’s remarks calling this “utter rubbish” undermine blogs as a place to criticize science. I think its good to avoid calling a paper or part of a paper bullshit in a blog and instead keep them as civil places to have meaningful discussion, not just a refuge of the angry. Using pejorative language and then defending it in the comments makes it hard to take comments seriously.
Ted, if you’re so concerned about civility, why would you highlight what you consider to be inappropriate language both here and over at your own post?
Seems to me like you’re repeatedly emphasizing the wrong part of the post.
I think “utter rubbish” is perfectly civil language. Its user (who didn’t use “bullshit”) has explicated his reasoning, so if that is what he considers… Blogs are not bound by the formal etiquette of science papers, nor should they be.
Ted – thanks for your interest – I’ll respond to your post there.
The “utter rubbish” was stronger language than I normally use, but I thought it was worth some, um, extreme editorialising. Blogs aren’t part of the formal literature, so I don’t see why we have to avoid calling spades spades. As Lee pointed out, I did give my reasoning.
If I hadn’t written “utter rubbish” would you have written your blog post?
The definition of civility in language is “if you can imagine a Jane Austin character saying it then it is sufficiently civil enough”
@jeremy.fox
I also find your response disappointing, and slightly unfair.
First, I wrote my response to Bob because I believed that he had unfairly smeared a very interesting paper with terms such as ‘utter rubbish’, and because posts subsequent to it endorsed his view with unquestioning acceptance. Had he restricted his post to the statistical matter at hand without the use of loaded and unfair language I would not have seen much need to respond to it.
Second, I don’t really accept your claim that I am invoking authority figures or using Catholic Church tactics. Anyone not familiar with this topic who read Bob’s comments at face value would reasonably conclude that Maestre and colleagues are foolish folk who know nothing about statistics. So it therefore seemed (and still seems) only fair to point out to readers that these authors are competent folk who do not normally write ‘utter rubbish’. This is not ‘invoking authority’, merely defending the authors against what I perceive as an unfair attack.
Third, about my views regarding blogs versus peer reviewed literature, which I suspect differ greatly from Bob’s or yours. Blogs are definitely entertaining and sometimes deliver useful insights but they should not be seen as operating at the same level as peer reviewed literature. As an example, the blogosphere contains all sorts of ‘scientific’ points of view and reasoning about whether or not humans are responsible for global climate change, but only a subset of these views normally appear in the peer reviewed literature, i.e., those that are actually supported by scientific evidence.
Finally, it seems odd that you seek to criticize only the posts of only those who disagree with Bob rather than those by Bob or any of his supporters, especially given that both John Bruno’s and my post contain far more collegial language than Bob’s one does. This could make you appear as somewhat partisan on this topic.
David – if you wanted to show that Maestre et al. are not ‘foolish fellows’ (something I don’t believe – I was only criticising that one sentence) then you could have shown the problems in my argument. Instead you used the authority of one of the authors (who may not have been responsible for that sentence). What is that other than an appeal to authority?
I haven’t seen anyone here arguing that blogs are at the same level as the peer reviewed literature, and I doubt anyone would. But I don’t think that means they can be dismissed out of hand. Yes, all sorts of rubbish get written on blogs, but it’s out there and can be criticised, so if you think I’m wrong you can explain why I’m wrong.
Mike, I tried to write a rebuttal to Bob’s post that addressed his concerns, not to simply recapitulate his editorializing. I’ve never met Bob, but I’m sure he’s a perfectly nice guy.
Bob, I would have written my own post no matter what. Sure blogs shouldn’t be held to the same editorial standards as peer review. But I just happen to think that at the same time it can be a slippery slope from informal discussion to polemical nastiness. I also agree with your larger point, errors in variables are important and something we don’t talk about in ecology. But its a criticism that can be leveled at pretty much any study that uses a regression design. Your post just read more as “Here’s this new paper that came out in Science and I think it has x y and z problems” and less as “Here’s a paper in Science and it highlights a common problem in ecological statistics. For example these other papers have the same problem, but look at these papers that have done a good job addressing this issue”
That aside though, I think it’d be good to explore this problem a bit more and find some papers that really address some of these issues.
Bob,
Re your point about appeals to authority. I don’t think this is as black and white as you are suggesting. This paper was apparently being worked on when Maestre was visiting Gotelli’s group last summer, and Maestre and Gotelli occupy two of the three first positions on the authorship list (the third is a postdoc in Maestre’s lab). I still cannot see how it is possible to defend the authors leading this work without actually saying who they are.
Re your second point. Jeremy’s strongly worded response to my initial comment (which I thought was rather benign) suggests that he does indeed place considerably more importance on scientific blog posts than I do. However I dont think I ever said that they should be dismissed out of hand.
@David,
As I said over on Oikos blog, my first response to your comments was overly strident. But it doesn’t have anything to do with my attaching more importance to blogs than you do I probably do attach more importance to blogs than you do, but that’s not why I reacted as I did. I reacted as I did because I believe that even in the most casual venue (be it a blog, a conversation, an email, or whatever), scientists should not resort to proof by authority. Thank you for clarifying that that was not your intent, although I continue to believe that was the most natural reading of your comment.
On other issues, we will have to agree to disagree:
I believe that it was perfectly clear on its face that Bob’s post was criticizing a specific, quoted sentence from Maestre et al., not the authors or their competence. With all due respect, I believe your have misunderstood Bob’s post based on your dislike of his tone, and of the venue in which he published.
I believe it is fine to strongly criticize statements from even prominent authors, as long as the reasons for one’s criticisms are explained, and that no criticism of any statement carries any implied criticism of the authors of that statement. Based on my experience as a handling editor and author, I believe that my views on this point are common. Of course, there is room for legitimate disagreement on this point.
I believe that nothing about Bob’s post was “unfair.” What would have been unfair would have been for him to not explain his reasons, but he explained them at length. And as previously noted, anyone is free to comment, so he has not unfairly denied anyone an opportunity to reply.
I agree that there is lots of rubbish in the blogosphere, but disagree that this is relevant. Why should the fact that there is much rubbish elsewhere on the blogosphere have anything to do with the validity of Bob’s comments? Similarly, as I’m sure you recognize, there is rubbish in the peer reviewed literature as well. But this is irrelevant to the validity of any particular paper, which surely ought to be judged solely on its own merits. Surely you don’t simply take for granted that the peer reviewed literature contains no mistakes, or only very minor mistakes? I believe it is unfortunate that you appear comfortable with letting the venue in which something was published color your view of it after you’ve read it. Please do not misunderstand, I think it is perfectly fine if, for instance, you were to generally avoid reading blogs because you see them as mostly rubbish. That’s absolutely fair enough. But once you’ve chosen to read something, surely you can respond to it on its merits, and distinguish any objections you have to the tone with objections to the merits.
No one has suggested that you defend Maestre et al. without naming the authors. What I and others have argued is that you and John should not defend the content of Maestre et al. by invoking anything about the authors. For instance, I am unclear of the relevance of the fact that Maestre and Gotelli worked closely together on the paper. No one has suggested that they made a mistake because they failed to work sufficiently closely.
I am unclear on the issue on which you think I could be perceived as “partisan”. I believe it is quite clear from my comments, and my own blog post, that my concern was with the way in which you and John appeared to defend the content of Maestre et al. I did not comment on how Bob, or his supporters, have expressed their views, because I think they have expressed their views appropriately. I also stated explicitly on my blog post that I believe the general issue of errors in variables is an important and often-overlooked one which was legitimate to raise in this context. And I have published extensively on the broad topic of biodiversity and ecosystem function, including on methods for analyzing observational BDEF data, so my views on this broad topic also are perfectly clear. I wonder a little if, in suggesting that I could be seen as “partisan”, you merely meant an indirect, oblique, or polite criticism of some aspect of my writing. With respect, if that was your intent I would prefer if you would be more direct. I don’t equate directness with impoliteness, and prefer directness because directness is clear and easy to interpret.